Учебник по MapReduceУчебные пособия
Published on 2023-04-20 00:10:05 · 中文 · English · بالعربية · Español · हिंदीName · 日本語 · 中文繁體
MapReduce — это парадигма программирования, которая работает за кулисами Hadoop и обеспечивает масштабируемость и простое решение для обработки данных. В этом учебнике объясняется, что делает MapReduce и как он анализирует большие данные.
MapReduce — это модель программирования для написания приложений, которые могут обрабатывать большие данные параллельно на нескольких узлах. MapReduce предоставляет аналитические возможности для анализа больших объемов сложных данных.
Что такое большие данные?
Большие данные — это набор больших наборов данных, которые не могут быть обработаны с использованием традиционных вычислительных методов. Например, объем данных, который Facebook или Youtube нужен для сбора и управления каждый день, подпадает под зонтик больших данных. Однако большие данные связаны не только с масштабом и объемом, но и с одним или несколькими из следующих — скоростью, разнообразием, объемом и сложностью.
Почему MapReduce?
Традиционные корпоративные системы обычно имеют центральный сервер для хранения и обработки данных. На следующей схеме показана принципиальная схема традиционной корпоративной системы. Традиционная модель, безусловно, не подходит для обработки огромных объемов масштабируемых данных, и стандартные серверы баз данных не могут ее вместить. Кроме того, централизованные системы создают чрезмерные узкие места при обработке нескольких файлов одновременно.
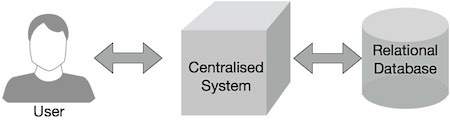
Google решил это узкое место с помощью алгоритма под названием MapReduce. MapReduce разделяет задачу на небольшие части и распределяет их по нескольким компьютерам. Затем результаты группируются вместе и интегрируются для формирования набора данных результатов.
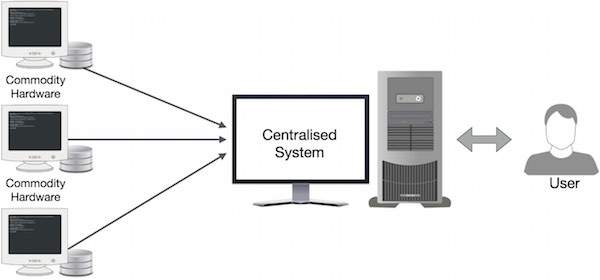
Как работает MapReduce?
Алгоритм MapReduce состоит из двух важных задач: Map и Reduce.
Задача Map берет один набор данных и преобразует его в другой набор данных, где отдельные элементы разбиваются на кортежи (пары ключ-значение).
Задача Reduce принимает выходные данные Map в качестве входных данных и объединяет эти кортежи данных (пары ключ-значение) в меньший набор кортежей.
Задача уменьшения всегда выполняется после задания карты.
Теперь давайте рассмотрим каждый этап и попробуем понять, насколько они важны.
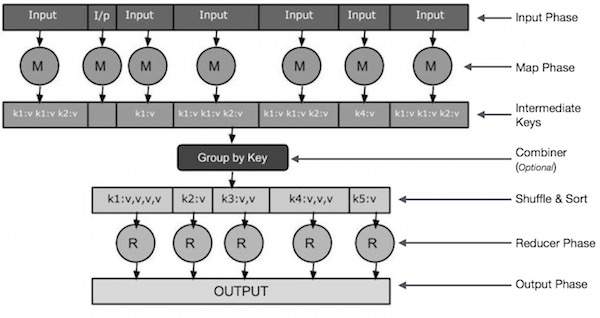 Input stage - здесь у нас есть считыватель записей, который переводит каждую запись во входной файл и отправляет проанализированные данные картографу в виде пар ключ-значение.
Map-Map — это определяемая пользователем функция, которая принимает ряд пар ключ-значение и обрабатывает каждую пару ключ-значение для создания нуля или более пар ключ-значение.
Промежуточный ключ — пары «ключ-значение», генерируемые картографом, называются промежуточными ключами.
Combiner-Combiner — это упрощение локализации, которое группирует аналогичные данные из фазы сопоставления в распознаваемые множества. Он принимает среднюю клавишу картографа в качестве входных данных и применяет пользовательский код к агрегированным значениям в небольшом диапазоне картографов. Он не является частью основного алгоритма MapReduce; Это необязательно.
Задачи «Перетасовка» и «Сортировка-уменьшение» начинаются с шагов «Перетасовка» и «Сортировка». Он загружает сгруппированные пары "ключ-значение" на локальный компьютер, на котором работает Reducer. Отдельные пары "ключ-значение" сортируются в больший список данных. Списки данных объединяют эквивалентные ключи, чтобы легко перебирать их значения в задаче Reducer.
Reducer - Reducer принимает сгруппированные данные пары ключ-значение в качестве входных данных и запускает функцию Reducer на каждом из них. Здесь данные могут быть агрегированы, отфильтрованы и объединены различными способами, и требуется обширная обработка. Когда выполнение завершено, он предоставляет ноль или более пар ключ-значение к последнему шагу.
Выходной этап - На выходном этапе у нас есть модуль форматирования вывода, который преобразует конечные пары ключ-значение из функции Reduce и записывает их в файл с помощью записывающей записи.
Input stage - здесь у нас есть считыватель записей, который переводит каждую запись во входной файл и отправляет проанализированные данные картографу в виде пар ключ-значение.
Map-Map — это определяемая пользователем функция, которая принимает ряд пар ключ-значение и обрабатывает каждую пару ключ-значение для создания нуля или более пар ключ-значение.
Промежуточный ключ — пары «ключ-значение», генерируемые картографом, называются промежуточными ключами.
Combiner-Combiner — это упрощение локализации, которое группирует аналогичные данные из фазы сопоставления в распознаваемые множества. Он принимает среднюю клавишу картографа в качестве входных данных и применяет пользовательский код к агрегированным значениям в небольшом диапазоне картографов. Он не является частью основного алгоритма MapReduce; Это необязательно.
Задачи «Перетасовка» и «Сортировка-уменьшение» начинаются с шагов «Перетасовка» и «Сортировка». Он загружает сгруппированные пары "ключ-значение" на локальный компьютер, на котором работает Reducer. Отдельные пары "ключ-значение" сортируются в больший список данных. Списки данных объединяют эквивалентные ключи, чтобы легко перебирать их значения в задаче Reducer.
Reducer - Reducer принимает сгруппированные данные пары ключ-значение в качестве входных данных и запускает функцию Reducer на каждом из них. Здесь данные могут быть агрегированы, отфильтрованы и объединены различными способами, и требуется обширная обработка. Когда выполнение завершено, он предоставляет ноль или более пар ключ-значение к последнему шагу.
Выходной этап - На выходном этапе у нас есть модуль форматирования вывода, который преобразует конечные пары ключ-значение из функции Reduce и записывает их в файл с помощью записывающей записи.
Попробуем разобраться в двух задачах Map &f Reduce с помощью небольшой диаграммы-
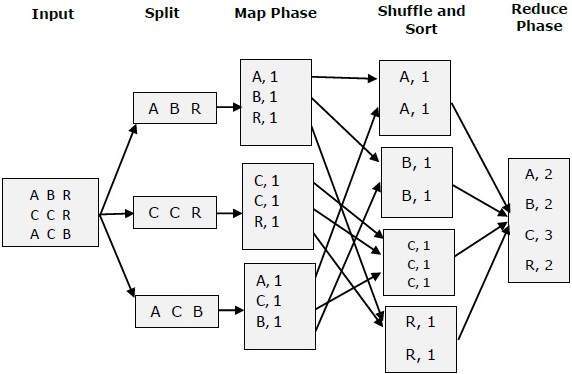
MapReduce - Пример
Давайте возьмем реальный пример, чтобы понять силу MapReduce. Twitter получает около 500 миллионов твитов в день, или почти 3000 твитов в секунду. На следующей схеме показано, как Tweeter управляет своими твитами с помощью MapReduce.
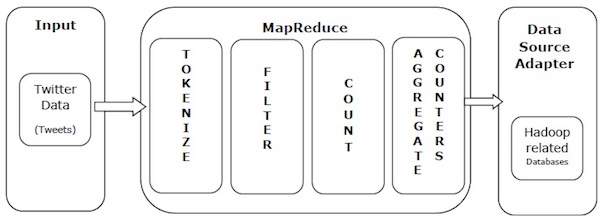
Как показано на рисунке, алгоритм MapReduce выполняет следующие действия:
Tokenize ( Токенизировать - Помечайте твиты как сопоставления тегов и записывайте их в пары ключ-значение.
Фильтр — отфильтровывайте нежелательные слова из карты тегов и записывайте отфильтрованную карту в виде пар ключ-значение.
Count — каждое слово генерирует счетчик токенов.
Агрегатные счетчики - Подготавливает совокупность значений счетчиков в небольшие, управляемые единицы.