マップリデュースチュートリアル学習マニュアル
Published on 2023-04-20 00:10:05 · 中文 · English · بالعربية · Español · हिंदीName · Русский язык · 中文繁體
MapReduceは、Hadoopの舞台裏で実行されるプログラミングパラダイムであり、スケーラビリティとシンプルなデータ処理ソリューションを提供します。 このチュートリアルでは、MapReduce の機能とその分析方法について説明します。
MapReduceは、複数のノードでビッグデータを並列に処理できるアプリケーションを作成するためのプログラミングモデルです。 MapReduceは、大量の複雑なデータを分析するための分析機能を提供します。
ビッグデータとは?
ビッグデータは、従来のコンピューティング技術では処理できない大規模なデータセットのコレクションです。 たとえば、FacebookやYoutubeが毎日収集および管理するために必要なデータの量は、ビッグデータの傘下にあります。 ただし、ビッグデータは規模と量だけでなく、速度、多様性、量、複雑さの1つ以上についても重要です。
なぜマップリデュースなのか?
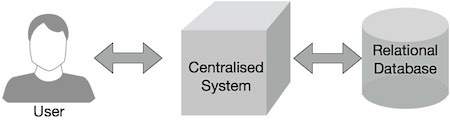
従来のエンタープライズシステムには、通常、データを保存および処理するための中央サーバーがあります。 次の図は、従来のエンタープライズ システムの概略図を示しています。 従来のモデルは、大量のスケーラブルなデータの処理には適しておらず、標準のデータベースサーバーはそれに対応できません。 さらに、集中型システムは、複数のファイルを同時に処理するときに過度のボトルネックを作成します。
GoogleはMapReduceと呼ばれるアルゴリズムを使用してこのボトルネックを解決しました。 MapReduceは、タスクを小さな部分に分割し、複数のコンピューターに配布します。 次に、結果をグループ化して統合し、結果データセットを形成します。
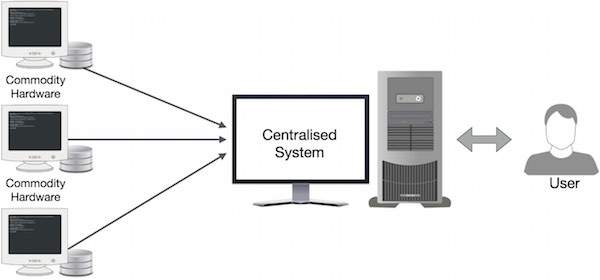
MapReduceはどのように機能しますか?
MapReduce アルゴリズムは、マップと削減という 2 つの重要なタスクで構成されています。
Map タスクは、1 つのデータ セットを取得し、それを別のデータ セットに変換し、個々の要素がタプル (キーと値のペア) に分割されます。
Reduce タスクは、Map の出力を入力として受け取り、これらのデータ タプル (キーと値のペア) を結合して、より小さなタプルのセットにします。
reduce タスクは、常にマップ ジョブの後に実行されます。
それでは、各段階を見て、それらがどれほど重要であるかを理解してみましょう。
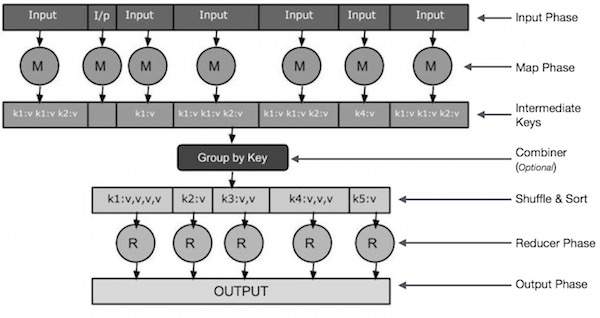 入力ステージ - ここには、入力ファイル内の各レコードを変換し、解析されたデータをキーと値のペアの形式でマッパーに送信するレコードリーダーがあります。
Map-Map は、一連のキーと値のペアを受け取り、各キーと値のペアを処理して 0 個以上のキーと値のペアを生成するユーザー定義関数です。
中間キー - マッパーによって生成されたキーと値のペアは中間キーと呼ばれます。
Combiner-Combiner は、マッピングフェーズの類似データを認識可能なセットにグループ化するローカリゼーション簡略化子です。 マッパーの中央キーを入力として受け取り、ユーザー定義コードを適用して、狭い範囲のマッパー内の値を集計します。 これはメインのMapReduceアルゴリズムの一部ではありません。 これはオプションです。
シャッフル タスクと並べ替え - 削減タスクは、シャッフル ステップと並べ替えステップから始まります。 グループ化されたキーと値のペアを、Reducer を実行しているローカルマシンにダウンロードします。 個々のキーと値のペアは、より大きなデータリストにソートされます。 データリストは、同等のキーを組み合わせて、Reducerタスクで値を簡単に反復処理します。
Reducer - Reducer は、グループ化されたキーと値のペア データを入力として受け取り、それぞれに対して Reducer 関数を実行します。 ここでは、さまざまな方法でデータを集約、フィルタリング、および組み合わせることができ、広範な処理が必要です。 実行が完了すると、最後のステップに 0 個以上のキーと値のペアが提供されます。
出力ステージ - 出力フェーズには、Reduce関数から最終的なキーと値のペアを変換し、レコードライターを使用してファイルに書き込む出力フォーマッタがあります。
入力ステージ - ここには、入力ファイル内の各レコードを変換し、解析されたデータをキーと値のペアの形式でマッパーに送信するレコードリーダーがあります。
Map-Map は、一連のキーと値のペアを受け取り、各キーと値のペアを処理して 0 個以上のキーと値のペアを生成するユーザー定義関数です。
中間キー - マッパーによって生成されたキーと値のペアは中間キーと呼ばれます。
Combiner-Combiner は、マッピングフェーズの類似データを認識可能なセットにグループ化するローカリゼーション簡略化子です。 マッパーの中央キーを入力として受け取り、ユーザー定義コードを適用して、狭い範囲のマッパー内の値を集計します。 これはメインのMapReduceアルゴリズムの一部ではありません。 これはオプションです。
シャッフル タスクと並べ替え - 削減タスクは、シャッフル ステップと並べ替えステップから始まります。 グループ化されたキーと値のペアを、Reducer を実行しているローカルマシンにダウンロードします。 個々のキーと値のペアは、より大きなデータリストにソートされます。 データリストは、同等のキーを組み合わせて、Reducerタスクで値を簡単に反復処理します。
Reducer - Reducer は、グループ化されたキーと値のペア データを入力として受け取り、それぞれに対して Reducer 関数を実行します。 ここでは、さまざまな方法でデータを集約、フィルタリング、および組み合わせることができ、広範な処理が必要です。 実行が完了すると、最後のステップに 0 個以上のキーと値のペアが提供されます。
出力ステージ - 出力フェーズには、Reduce関数から最終的なキーと値のペアを変換し、レコードライターを使用してファイルに書き込む出力フォーマッタがあります。
小さな図の助けを借りて、MapとReduceの2つのタスクを理解してみましょう。
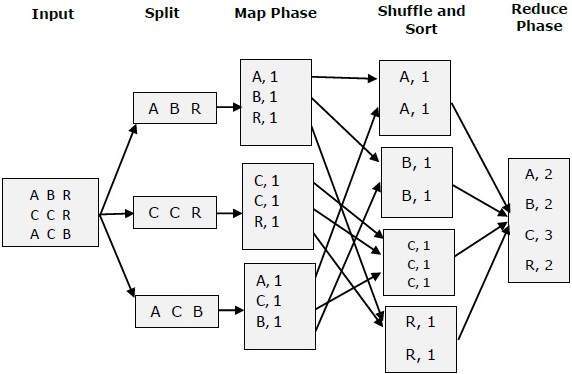
マップリデュース - 例
MapReduceの力を理解するために、実際の例を見てみましょう。 Twitterは1日あたり約5億ツイート、つまり毎秒約3,000ツイートを受け取ります。 次の図は、Tweeter が MapReduce を使用してツイートを管理する方法を示しています。
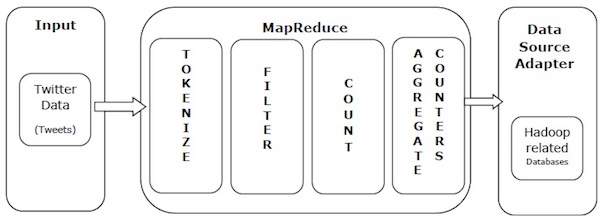
図に示すように、MapReduceアルゴリズムは次のことを行います。
トークン化 - ツイートをタグマッピングとしてマークし、キーと値のペアに書き込みます。
フィルター - タグマップから不要な単語を除外し、フィルタリングされたマップをキーと値のペアとして書き込みます。
カウント - 各単語はトークンカウンターを生成します。
カウンターの集計 - カウンター値の集計を小さく管理しやすい単位に準備します。