MapReduce tutorialहात- पुस्तिका सिखा रहा है
Published on 2023-04-20 00:10:05 · 中文 · English · بالعربية · Español · 日本語 · Русский язык · 中文繁體
MapReduce एक प्रोग्रामिंग प्रतिमान है जो Hadoop के पर्दे के पीछे चलता है और स्केलेबिलिटी और एक सरल डेटा प्रोसेसिंग समाधान प्रदान करता है। यह ट्यूटोरियल बताता है कि MapReduce क्या करता है और यह बड़े डेटा का विश्लेषण कैसे करता है।
MapReduce अनुप्रयोगों को लिखने के लिए एक प्रोग्रामिंग मॉडल है जो कई नोड्स पर समानांतर में बड़े डेटा को संसाधित कर सकता है। MapReduce बड़ी मात्रा में जटिल डेटा का विश्लेषण करने के लिए विश्लेषणात्मक क्षमताएं प्रदान करता है।
बिग डेटा क्या है?
बिग डेटा बड़े डेटा सेटों का एक संग्रह है जिसे पारंपरिक कंप्यूटिंग तकनीकों का उपयोग करके संसाधित नहीं किया जा सकता है। उदाहरण के लिए, फेसबुक या यूट्यूब को हर दिन एकत्र करने और प्रबंधित करने के लिए जितना डेटा चाहिए, वह बड़े डेटा की छतरी के नीचे आता है। हालांकि, बड़ा डेटा न केवल पैमाने और मात्रा के बारे में है, बल्कि निम्नलिखित में से एक या अधिक के बारे में भी है - गति, विविधता, मात्रा और जटिलता।
MapReduces क्यों?
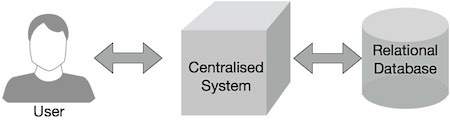
पारंपरिक एंटरप्राइज़ सिस्टम में आमतौर पर डेटा को संग्रहीत और संसाधित करने के लिए एक केंद्रीय सर्वर होता है। निम्नलिखित आरेख एक पारंपरिक उद्यम प्रणाली के योजनाबद्ध आरेख को दर्शाता है। पारंपरिक मॉडल निश्चित रूप से स्केलेबल डेटा की भारी मात्रा को संभालने के लिए उपयुक्त नहीं है, और मानक डेटाबेस सर्वर इसे समायोजित नहीं कर सकते हैं। इसके अलावा, केंद्रीकृत सिस्टम एक ही समय में कई फ़ाइलों को संसाधित करते समय अत्यधिक बाधाएं पैदा करते हैं।
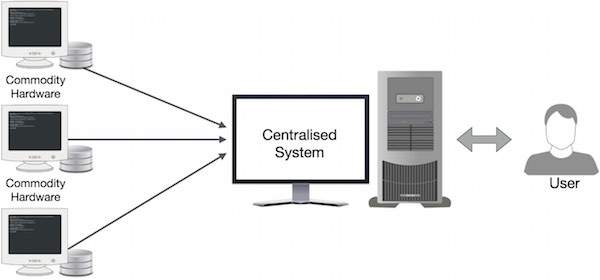
Google ने MapReduce नामक एल्गोरिथ्म का उपयोग करके इस अड़चन को हल किया। MapReduce एक कार्य को छोटे भागों में विभाजित करता है और उन्हें कई कंप्यूटरों में वितरित करता है। परिणामों को फिर एक साथ समूहीकृत किया जाता है और परिणाम डेटासेट बनाने के लिए एकीकृत किया जाता है।
MapReduc कैसे काम करता है?
MapReduce एल्गोरिथ्म में दो महत्वपूर्ण कार्य होते हैं, मैप और रिड्यूस।
मैप कार्य डेटा का एक सेट लेता है और इसे डेटा के दूसरे सेट में बदल देता है, जहां व्यक्तिगत तत्वों को ट्यूपल (कुंजी-मूल्य जोड़े) में विभाजित किया जाता है।
रिड्यूस टास्क मैप के आउटपुट को इनपुट के रूप में लेता है और इन डेटा ट्यूपल्स (कुंजी-मूल्य जोड़े) को ट्यूपल के एक छोटे सेट में जोड़ता है।
मानचित्र कार्य के बाद रिड्यूस कार्य हमेशा निष्पादित किया जाता है।
अब आइए प्रत्येक चरण पर एक नज़र डालें और यह समझने की कोशिश करें कि वे कितने महत्वपूर्ण हैं।
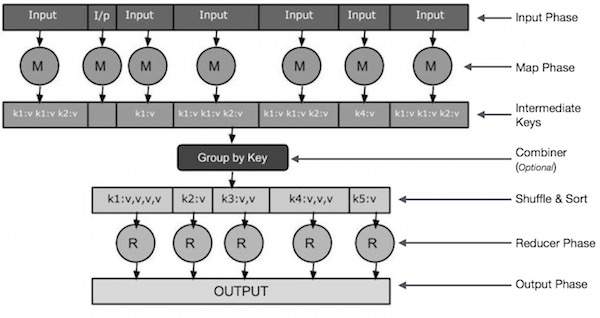 इनपुट चरण - यहां हमारे पास एक रिकॉर्ड रीडर है जो इनपुट फ़ाइल में प्रत्येक रिकॉर्ड का अनुवाद करता है और कुंजी-मूल्य जोड़े के रूप में मैपर को पार्स किए गए डेटा भेजता है।
मैप-मैप एक उपयोगकर्ता-परिभाषित फ़ंक्शन है जो कुंजी-मूल्य जोड़े की एक श्रृंखला लेता है और शून्य या अधिक कुंजी-मूल्य जोड़े का उत्पादन करने के लिए प्रत्येक कुंजी-मूल्य जोड़ी को संसाधित करता है।
मध्यवर्ती कुंजी- मैपर द्वारा उत्पन्न कुंजी-मान जोड़े को मध्यवर्ती कुंजी कहा जाता है।
कंबाइनर-कंबाइनर एक स्थानीयकरण सरलीकरण है जो मैपिंग चरण से समान डेटा को पहचानने योग्य सेट में समूहीकृत करता है। यह मैपर की मध्य कुंजी को इनपुट के रूप में लेता है और मैपर की एक छोटी श्रृंखला के भीतर कुल मूल्यों के लिए उपयोगकर्ता-परिभाषित कोड लागू करता है। यह मुख्य MapReduce एल्गोरिथ्म का हिस्सा नहीं है; यह वैकल्पिक है।
शफल और सॉर्ट-रिड्यूस कार्य शफल और सॉर्ट चरणों के साथ शुरू होते हैं। यह समूहीकृत कुंजी-मान जोड़े को रिड्यूसर चलाने वाली स्थानीय मशीन में डाउनलोड करता है। व्यक्तिगत कुंजी-मान जोड़े डेटा की एक बड़ी सूची में क्रमबद्ध किए जाते हैं। डेटा सूचियाँ एक रिड्यूसर कार्य में अपने मानों पर आसानी से पुनरावृत्ति करने के लिए समकक्ष कुंजियों को जोड़ती हैं।
रिड्यूसर - रिड्यूसर समूहीकृत कुंजी-मूल्य जोड़ी डेटा को इनपुट के रूप में लेता है और उनमें से प्रत्येक पर एक रिड्यूसर फ़ंक्शन चलाता है। यहां, डेटा को विभिन्न तरीकों से एकत्रित, फ़िल्टर और संयुक्त किया जा सकता है, और व्यापक प्रसंस्करण की आवश्यकता होती है। जब निष्पादन पूरा हो जाता है, तो यह अंतिम चरण में शून्य या अधिक कुंजी-मान जोड़े प्रदान करता है।
आउटपुट चरण - आउटपुट चरण में, हमारे पास एक आउटपुट प्रारूपक है जो अंतिम कुंजी-मूल्य जोड़े को रिड्यूस फ़ंक्शन से परिवर्तित करता है और उन्हें रिकॉर्ड लेखक का उपयोग करके फ़ाइल में लिखता है।
इनपुट चरण - यहां हमारे पास एक रिकॉर्ड रीडर है जो इनपुट फ़ाइल में प्रत्येक रिकॉर्ड का अनुवाद करता है और कुंजी-मूल्य जोड़े के रूप में मैपर को पार्स किए गए डेटा भेजता है।
मैप-मैप एक उपयोगकर्ता-परिभाषित फ़ंक्शन है जो कुंजी-मूल्य जोड़े की एक श्रृंखला लेता है और शून्य या अधिक कुंजी-मूल्य जोड़े का उत्पादन करने के लिए प्रत्येक कुंजी-मूल्य जोड़ी को संसाधित करता है।
मध्यवर्ती कुंजी- मैपर द्वारा उत्पन्न कुंजी-मान जोड़े को मध्यवर्ती कुंजी कहा जाता है।
कंबाइनर-कंबाइनर एक स्थानीयकरण सरलीकरण है जो मैपिंग चरण से समान डेटा को पहचानने योग्य सेट में समूहीकृत करता है। यह मैपर की मध्य कुंजी को इनपुट के रूप में लेता है और मैपर की एक छोटी श्रृंखला के भीतर कुल मूल्यों के लिए उपयोगकर्ता-परिभाषित कोड लागू करता है। यह मुख्य MapReduce एल्गोरिथ्म का हिस्सा नहीं है; यह वैकल्पिक है।
शफल और सॉर्ट-रिड्यूस कार्य शफल और सॉर्ट चरणों के साथ शुरू होते हैं। यह समूहीकृत कुंजी-मान जोड़े को रिड्यूसर चलाने वाली स्थानीय मशीन में डाउनलोड करता है। व्यक्तिगत कुंजी-मान जोड़े डेटा की एक बड़ी सूची में क्रमबद्ध किए जाते हैं। डेटा सूचियाँ एक रिड्यूसर कार्य में अपने मानों पर आसानी से पुनरावृत्ति करने के लिए समकक्ष कुंजियों को जोड़ती हैं।
रिड्यूसर - रिड्यूसर समूहीकृत कुंजी-मूल्य जोड़ी डेटा को इनपुट के रूप में लेता है और उनमें से प्रत्येक पर एक रिड्यूसर फ़ंक्शन चलाता है। यहां, डेटा को विभिन्न तरीकों से एकत्रित, फ़िल्टर और संयुक्त किया जा सकता है, और व्यापक प्रसंस्करण की आवश्यकता होती है। जब निष्पादन पूरा हो जाता है, तो यह अंतिम चरण में शून्य या अधिक कुंजी-मान जोड़े प्रदान करता है।
आउटपुट चरण - आउटपुट चरण में, हमारे पास एक आउटपुट प्रारूपक है जो अंतिम कुंजी-मूल्य जोड़े को रिड्यूस फ़ंक्शन से परिवर्तित करता है और उन्हें रिकॉर्ड लेखक का उपयोग करके फ़ाइल में लिखता है।
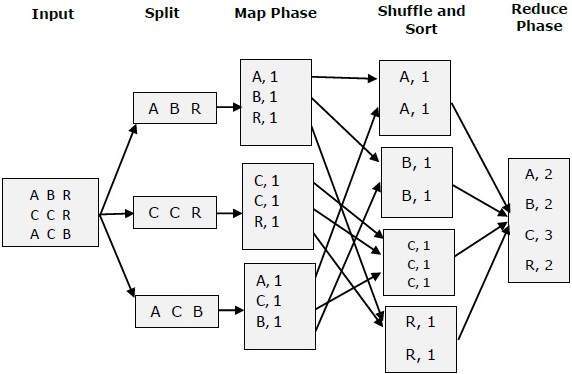
आइए एक छोटे से आरेख की सहायता से मैप एंड एफ रिड्यूस के दो कार्यों को समझने की कोशिश करते हैं-
MapReduce - उदाहरण
आइए MapReduce की शक्ति को समझने के लिए एक वास्तविक दुनिया का उदाहरण लें। ट्विटर को प्रति दिन लगभग 500 मिलियन ट्वीट्स या प्रति सेकंड लगभग 3,000 ट्वीट्स प्राप्त होते हैं। निम्न आरेख दिखाता है कि MapReduce की मदद से ट्वीटर अपने ट्वीट्स का प्रबंधन कैसे करता है।
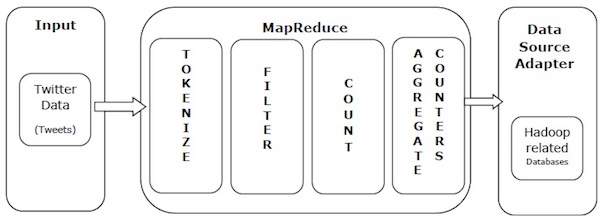
जैसा कि चित्र में दिखाया गया है, MapReduce एल्गोरिथ्म निम्नलिखित करता है-
टोकन - ट्वीट्स को टैग मैपिंग के रूप में चिह्नित करें और उन्हें कुंजी-मूल्य जोड़े में लिखें।
फ़िल्टर - टैग मैप से अवांछित शब्दों को फ़िल्टर करें और फ़िल्टर किए गए मानचित्र को कुंजी-मान जोड़े के रूप में लिखें।
गिनती - प्रत्येक शब्द एक टोकन काउंटर उत्पन्न करता है।
एग्रीगेट काउंटर - छोटी, प्रबंधनीय इकाइयों में काउंटर मूल्यों का एक समुच्चय तैयार करता है।