MapReduce Tutoriallearning manual
Published on 2023-04-20 00:10:05 · 中文 · بالعربية · Español · हिंदीName · 日本語 · Русский язык · 中文繁體
MapReduce is a programming paradigm that runs in the Hadoop backend, providing scalability and simple data processing solutions. This tutorial explains the functionality of MapReduce and how it analyzes big data.
MapReduce is a programming model used to write applications that can process big data in parallel on multiple nodes. MapReduce provides analysis functionality for analyzing large amounts of complex data.
What is big data?
Big data is a collection of large datasets that cannot be processed using traditional computing techniques. For example, the amount of data that Facebook or YouTube needs to collect and manage on a daily basis falls under the category of big data. However, big data not only involves scale and quantity, but also one or more of the following aspects - speed, diversity, quantity, and complexity.
Why MapReduce?
Traditional enterprise systems typically have a central server to store and process data. The following diagram depicts a schematic diagram of a traditional enterprise system. Traditional models are certainly not suitable for handling massive and scalable data, and standard database servers are also unable to accommodate it. In addition, centralized systems can create too many bottlenecks when processing multiple files simultaneously.
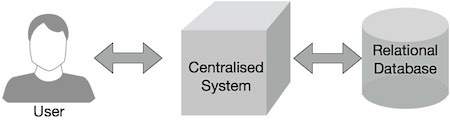
Google solved this bottleneck problem using an algorithm called MapReduce. MapReduce divides a task into small parts and assigns them to multiple computers. Afterwards, gather the results together and integrate them to form a result dataset.
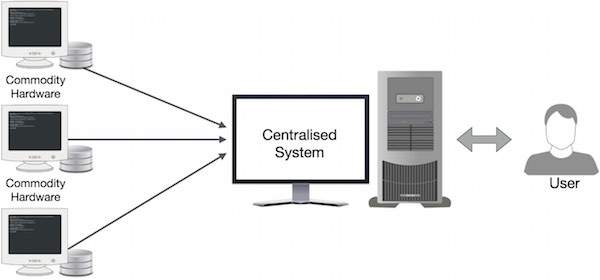
How does MapReduce work?
The MapReduce algorithm consists of two important tasks, namely Map and Reduce.
The Map task takes a set of data and converts it into another set, where each element is decomposed into tuples (key value pairs).
The Reduce task takes the output of the Map as the input, and combines these data tuples (key value pairs) into a group of smaller tuples.
The reduce task is always executed after the map job.
Now let's take a look at each stage and try to understand their importance.
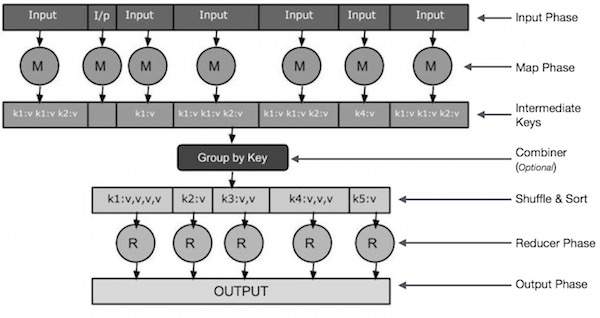 Input stage- Here we have a record reader that translates each record in the input file and sends the parsed data in the form of key value pairs to the mapper.
Map- Map is a user-defined function that takes a series of key value pairs and processes each pair to generate zero or more key value pairs.
Middle key- The key values generated by the mapper are symmetric as middle keys.
Combiner- A combiner is a localization reducer that groups similar data from the mapping stage into recognizable sets. It takes the middle key of the mapper as input and applies user-defined code to aggregate values within a small range of the mapper. It is not part of the main MapReduce algorithm; It is optional.
The Shuffle and Sort- Reduce task starts with the Shuffle and Sort steps. It downloads the grouped key value pairs to the local machine running Reducer. Each key value sorts the keys into a larger data list. The data list combines equivalent keys together to easily iterate their values in the Reducer task.
Reducer- Reducer takes grouped key value pairs of data as input and runs a Reducer function on each of them. Here, data can be aggregated, filtered, and combined in various ways, and requires extensive processing. After execution, it will provide zero or more key value pairs to the last step.
Output stage- In the output stage, we have an output formatter that converts the final key value pairs from the Reduce function and writes them to a file using a record writer.
Input stage- Here we have a record reader that translates each record in the input file and sends the parsed data in the form of key value pairs to the mapper.
Map- Map is a user-defined function that takes a series of key value pairs and processes each pair to generate zero or more key value pairs.
Middle key- The key values generated by the mapper are symmetric as middle keys.
Combiner- A combiner is a localization reducer that groups similar data from the mapping stage into recognizable sets. It takes the middle key of the mapper as input and applies user-defined code to aggregate values within a small range of the mapper. It is not part of the main MapReduce algorithm; It is optional.
The Shuffle and Sort- Reduce task starts with the Shuffle and Sort steps. It downloads the grouped key value pairs to the local machine running Reducer. Each key value sorts the keys into a larger data list. The data list combines equivalent keys together to easily iterate their values in the Reducer task.
Reducer- Reducer takes grouped key value pairs of data as input and runs a Reducer function on each of them. Here, data can be aggregated, filtered, and combined in various ways, and requires extensive processing. After execution, it will provide zero or more key value pairs to the last step.
Output stage- In the output stage, we have an output formatter that converts the final key value pairs from the Reduce function and writes them to a file using a record writer.
Let's try using a small image to understand Map& Reduce these two tasks-
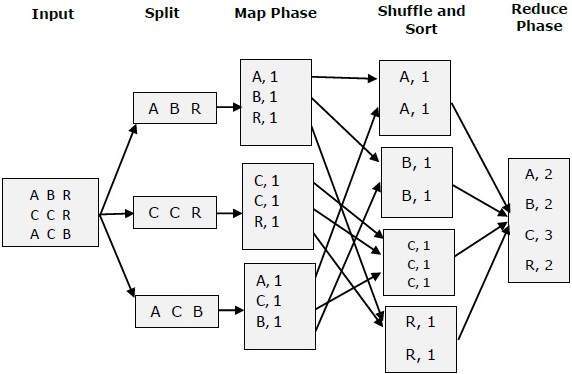
MapReduce - Example
Let's give a real-world example to understand the power of MapReduce. Twitter receives approximately 500 million tweets per day, or nearly 3000 tweets per second. The following figure shows how Tweeter manages its tweets with the help of MapReduce.
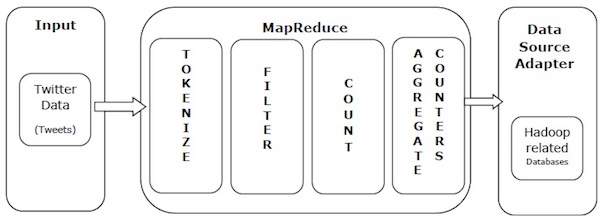
As shown in the figure, the MapReduce algorithm performs the following operations-
Token- Mark tweets as tag mappings and write them into key value pairs.
Filter- Filter out unnecessary words from the tag map and write the filtered map as key value pairs.
Count- Generate a token counter for each word.
Aggregate Counters- Prepare aggregates similar to counter values into small manageable units.