性能指标基础教程文档
收录于 2023-04-20 00:10:05 · بالعربية · English · Español · हिंदीName · 日本語 · Русский язык · 中文繁體
我们可以使用各种指标来评估ML算法,分类以及回归算法的性能。我们必须谨慎选择评估ML性能的指标,因为-
如何测量和比较ML算法的性能完全取决于您选择的指标。
您如何权衡各种特征在结果中的重要性,将完全取决于您选择的指标。
分类问题的绩效指标
在前面的章节中,我们讨论了分类及其算法。在这里,我们将讨论各种性能指标,这些指标可用于评估分类问题的预测。
混乱矩阵
这是衡量分类问题性能的最简单方法,其中输出可以是两种或多种类型的类。混淆矩阵不过是具有二维的表。 " Actual"和" Predicted",并且两个维度都具有" True Positives(TP)"," True Negatives(TN)"," False Positives(FP)"," False Negatives(FN)",如下所示-
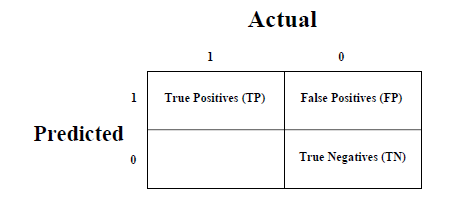
与混淆矩阵相关的术语的解释如下-
正值(TP)-数据点的实际类别和预测类别都为1的情况。
真负数(TN)-数据点的实际类别和预测类别都为0的情况。
假阳性(FP)-数据点的实际类别为0而数据点的预测类别为1的情况。
假阴性(FN)-数据点的实际类别为1,数据点的预测类别为0的情况。
我们可以使用
sklearn.metrics 的
confusion_matrix 函数来计算分类模型的混淆矩阵。
分类准确度
这是分类算法最常见的性能指标。可以将其定义为正确预测的数量,以其作为所有预测的比例。我们可以借助下面的公式通过混淆矩阵轻松地计算它-
$$Accuracy\:=\:\frac{TP+TN}{TP+FP+FN+TN}$$
我们可以使用
sklearn.metrics 的
accuracy_score 函数来计算分类模型的准确性。
分类报告
此报告包含"精度","召回率"," F1"和"支持"得分。它们解释如下-
精度
用于文档检索的精度可以定义为我们的ML模型返回的正确文档数。我们可以借助下面的公式通过混淆矩阵轻松地计算它-
$$ Precision \:= \:\ frac {TP} {TP + FN} $$
回忆或敏感性
召回率可以定义为我们的ML模型返回的肯定数。借助以下公式,我们可以轻松地通过混淆矩阵进行计算。
$$ Recall \:= \:\ frac {TP} {TP + FN} $$
专长
与召回相反,
特异性可以定义为我们的ML模型返回的负数。我们可以借助下面的公式通过混淆矩阵轻松地计算它-
$$ Specificity \:= \:\ frac {TN} {TN + FP} $$
支持
支持可以定义为每类目标值中真实响应的样本数。
F1得分
该分数将为我们提供精确度和查全率的谐和平均值。在数学上,F1分数是精度和召回率的加权平均值。 F1的最佳值为1,最差的为0。我们可以通过以下公式计算F1得分-
$$ F1 \:\:= \:2 *(precision * recall)/(precision + recall)$$
F1得分在准确性和召回率上的贡献相等。
我们可以使用sklearn.metrics的category_report函数来获取我们的分类模型的分类报告。
AUC(ROC曲线下的面积)
AUC(曲线下面积)-ROC(接收器工作特性)是一种性能指标,基于变化的阈值,用于分类问题。顾名思义,ROC是一条概率曲线,而AUC则测量了可分离性。简而言之,AUC-ROC度量标准将告诉我们有关模型区分类的能力。 AUC越高,模型越好。
从数学上讲,它可以通过在各种阈值下绘制TPR(真阳性率)即灵敏度或召回率与FPR(假阳性率)即1-Specific来创建。下图显示了ROC,在y轴上具有TPR且在x轴上具有FPR的AUC-
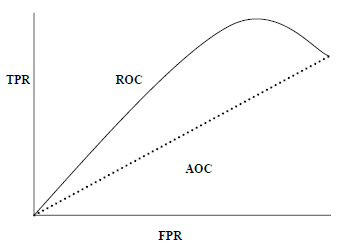
我们可以使用sklearn.metrics的roc_auc_score函数来计算AUC-ROC。
LOGLOSS(对数损失)
也称为Logistic回归损失或交叉熵损失。它基本上是根据概率估计定义的,并衡量分类模型的性能,其中输入是介于0和1之间的概率值。通过精确区分它可以更清楚地理解。众所周知,准确度是模型中预测的计数(预测值=实际值),而对数损失是基于预测值与实际标签相差多少的预测不确定性量。借助对数损失值,我们可以更准确地了解模型的性能。我们可以使用sklearn.metrics的log_loss函数来计算对数损失。
示例
以下是Python中的一个简单配方,它将使我们了解如何在二进制分类模型上使用上述解释的性能指标-
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from sklearn.metrics import roc_auc_score
from sklearn.metrics import log_loss
X_actual = [1, 1, 0, 1, 0, 0, 1, 0, 0, 0]
Y_predic = [1, 0, 1, 1, 1, 0, 1, 1, 0, 0]
results = confusion_matrix(X_actual, Y_predic)
print ('Confusion Matrix :')
print(results)
print ('Accuracy Score is',accuracy_score(X_actual, Y_predic))
print ('Classification Report : ')
print (classification_report(X_actual, Y_predic))
print('AUC-ROC:',roc_auc_score(X_actual, Y_predic))
print('LOGLOSS Value is',log_loss(X_actual, Y_predic))
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from sklearn.metrics import roc_auc_score
from sklearn.metrics import log_loss
X_actual = [1, 1, 0, 1, 0, 0, 1, 0, 0, 0]
Y_predic = [1, 0, 1, 1, 1, 0, 1, 1, 0, 0]
results = confusion_matrix(X_actual, Y_predic)
print ('Confusion Matrix :')
print(results)
print ('Accuracy Score is',accuracy_score(X_actual, Y_predic))
print ('Classification Report : ')
print (classification_report(X_actual, Y_predic))
print('AUC-ROC:',roc_auc_score(X_actual, Y_predic))
print('LOGLOSS Value is',log_loss(X_actual, Y_predic))
输出
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
Confusion Matrix :
[[3 3]
[1 3]]
Accuracy Score is 0.6
Classification Report :
precision recall f1-score support
0 0.75 0.50 0.60 6
1 0.50 0.75 0.60 4
micro avg 0.60 0.60 0.60 10
macro avg 0.62 0.62 0.60 10
weighted avg 0.65 0.60 0.60 10
AUC-ROC: 0.625
LOGLOSS Value is 13.815750437193334
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
Confusion Matrix :
[[3 3]
[1 3]]
Accuracy Score is 0.6
Classification Report :
precision recall f1-score support
0 0.75 0.50 0.60 6
1 0.50 0.75 0.60 4
micro avg 0.60 0.60 0.60 10
macro avg 0.62 0.62 0.60 10
weighted avg 0.65 0.60 0.60 10
AUC-ROC: 0.625
LOGLOSS Value is 13.815750437193334
回归问题的绩效指标
在前面的章节中,我们讨论了回归及其算法。在这里,我们将讨论各种性能指标,这些指标可用于评估回归问题的预测。
平均绝对误差(MAE)
这是回归问题中使用的最简单的误差度量。它基本上是预测值与实际值之间的绝对差的平均值之和。简而言之,借助MAE,我们可以了解预测的错误程度。 MAE不指示模型的方向,即不指示模型的性能不足或性能过高。以下是计算MAE的公式-
$$ MAE \:= \:\ frac {1} {n} \ sum \ mid Y- \ hat {Y} \ mid $$
这里,y =实际输出值
和$ \ hat {Y} $ =预测的输出值。
我们可以使用sklearn.metrics的mean_absolute_error函数来计算MAE。
均方误差(MSE)
MSE类似于MAE,但唯一的区别是,它在对所有实际值和预测输出值求和之前将它们求和,而不是使用绝对值来对其求平方。在以下等式中可以注意到差异-
$$ MSE \:= \:\ frac {1} {n} \ sum(Y- \ hat {Y})$$
这里,Y =实际输出值
和$ \ hat {Y} $ =预测的输出值。
我们可以使用sklearn.metrics的mean_squared_error函数来计算MSE。
R平方(R 2)
R Squared度量通常用于说明目的,并提供一组预测输出值与实际输出值之间的良好性或适合性的指示。以下公式将帮助我们理解它-
$$ R ^ {2} \:= \:1- \ frac {\ frac {1} {n} \ sum_ {i = 1} ^ n(Y_ {i}-\ hat {Y} _ { i})^ 2} {{\ frac {1} {n} \ sum_ {i = 1} ^ n(Y_ {i}-\ hat {Y} _ {i})^ 2}} $$
在上式中,分子为MSE,分母为Y值的方差。
我们可以使用sklearn.metrics的r2_score函数来计算R平方值。
示例
以下是Python中的一个简单配方,它将使我们了解如何在回归模型上使用上述解释的性能指标-
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
from sklearn.metrics import r2_score
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
X_actual = [5, -1, 2, 10]
Y_predic = [3.5, -0.9, 2, 9.9]
print ('R Squared =',r2_score(X_actual, Y_predic))
print ('MAE =',mean_absolute_error(X_actual, Y_predic))
print ('MSE =',mean_squared_error(X_actual, Y_predic))
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
from sklearn.metrics import r2_score
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
X_actual = [5, -1, 2, 10]
Y_predic = [3.5, -0.9, 2, 9.9]
print ('R Squared =',r2_score(X_actual, Y_predic))
print ('MAE =',mean_absolute_error(X_actual, Y_predic))
print ('MSE =',mean_squared_error(X_actual, Y_predic))
输出
# Filename : example.py
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
R Squared = 0.9656060606060606
MAE = 0.42499999999999993
MSE = 0.5674999999999999
# Copyright : 2020 By Lidihuo
# Author by : www.lidihuo.com
# Date : 2020-08-26
R Squared = 0.9656060606060606
MAE = 0.42499999999999993
MSE = 0.5674999999999999