Python爬虫教程学习手册
收录于 2023-04-20 00:10:05 · English · بالعربية · Español · हिंदीName · 日本語 · Русский язык · 中文繁體
什么是Python爬虫?
学习python爬虫之前,我们首先需要知道什么是爬虫。爬虫,即网络爬虫,大家可以理解为在网络上爬行的一只蜘蛛,互联网就比作一张大网,而蜘蛛便是在这张网上寻找自己的目标猎物。比如它在抓取一个网页,网站中的很多超链接就是形成了蜘蛛网,蜘蛛顺着超链接不断搜寻和爬去目标内容。
爬虫处理过程大致可以分为:发送请求——>获得页面——>解析页面——>抽取并储存内容。这也是我们用浏览器访问网页的过程。爬虫就是一个探测机器,它模拟人的行为去访问各个网站,拿到有用的信息。我们每天使用最多的百度,就是利用了爬虫技术,每天爬取大量网站信息用于用户的搜索和展示。
而由于python语音的特点,易配置,字符处理灵活和丰富的网络处理库,所以pytnon被很多技术人员做爬虫的首选语言,简单来讲,Python是非常适合开发网络爬虫的编程语言。
爬虫处理过程大致可以分为:发送请求——>获得页面——>解析页面——>抽取并储存内容。这也是我们用浏览器访问网页的过程。爬虫就是一个探测机器,它模拟人的行为去访问各个网站,拿到有用的信息。我们每天使用最多的百度,就是利用了爬虫技术,每天爬取大量网站信息用于用户的搜索和展示。
而由于python语音的特点,易配置,字符处理灵活和丰富的网络处理库,所以pytnon被很多技术人员做爬虫的首选语言,简单来讲,Python是非常适合开发网络爬虫的编程语言。
爬虫三要素
抓取: 爬虫向网站发送一个请求,获取到目标网页源代码,从中获取有价值的信息。Python中urllib库、requests库可帮助我们实现HTTP请求操作。 分析: 对获取的数据进行分析提取有价值的信息,提取信息常用到正则表达式。还可根据网页节点属性、CSS选择器或XPath来提取网页信息的库,如Beautiful Soup、pyquery、lxml等。 存储: 分析提取信息后,需进行存储,数据保存形式有TXT、JSON,还可以保存到MySQL和MongoDB中,用于远程访问
python爬虫的构架
Python爬虫的三要素:抓取、分析和存储网页的构架图如下:
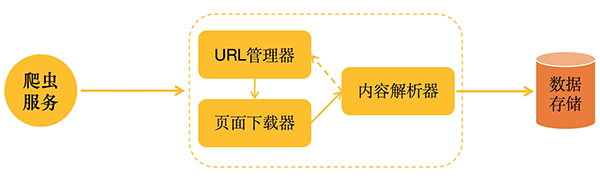 URL管理器: 管理待爬取的url集合和已爬取的url集合,传送待爬取的url给网页下载器;
网页下载器: 爬取url对应的网页,存储成字符串,传送给网页解析器;
内容解析器: 解析出有价值的数据,存储下来,同时补充url到URL管理器。
URL管理器: 管理待爬取的url集合和已爬取的url集合,传送待爬取的url给网页下载器;
网页下载器: 爬取url对应的网页,存储成字符串,传送给网页解析器;
内容解析器: 解析出有价值的数据,存储下来,同时补充url到URL管理器。
URL的含义
URL,即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
URL的格式由三部分组成:
1、第一部分是协议(或称为服务方式)。
2、第二部分是存有该资源的主机IP地址(有时也包括端口号)。
3、第三部分是主机资源的具体地址,如目录和文件名等。
爬虫爬取数据时必须要有一个目标的URL才可以获取数据,因此,它是爬虫获取数据的基本依据,准确理解它的含义对爬虫学习有很大帮助。
Python爬虫涉及知识点
要学习本教程,需要读者学习以下几个知识点:
Python基础知识:要用Python写爬虫首先需要了解Python的语言基础,按照本站的Python教程学习就能具备Python爬虫所需的知识。
Python中urllib和urllib2库的用法:urllib和urllib2库是学习Python爬虫最基本的库,利用这个库我们可以得到网页的内容,并对内容用正则表达式提取分析,得到我们想要的结果。
Python正则表达式:Python正则表达式是一种用来匹配字符串的强有力的武器。它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。
Python爬虫框架:如Scrapy框架、PySpider爬虫系统等
拓展阅读